When your workflow service is running, and how to tell if there is an error happened in the workflow instance? Actually, workflow already had a tracking mechanism built with it. We just need to do some configuration to enable it.
In the workflow tracking and tracing, we need to know 3 things:
1. Tracking Record - the tracking info emitted from workflow runtime
2. Tracking Participant - the subscription of the tracking record
3. Tracking Profile - the filter of the subscription
I will skip all the theory and concept detail, feel free to read them from MSDN.
I will share the detail of how to configure it only in this topic.
In a normal event, we would want to track the unusual incident in workflow only. So, I want to track the workflow instance if it is faulted, suspended, terminated or unhandled exception had occurred only. How?
Configure the Tracking Profile
Open up the config file. Insert the following XML node into the <system.serviceModel> node.
<tracking>
<profiles>
<trackingProfile name="TrackEverything" implementationVisibility="All">
<workflow activityDefinitionId="*">
<workflowInstanceQueries>
<workflowInstanceQuery>
<states>
<state name="Faulted"/>
<state name="Suspended"/>
<state name="Terminated"/>
<state name="UnhandledException"/>
</states>
</workflowInstanceQuery>
</workflowInstanceQueries>
</workflow>
</trackingProfile>
</profiles>
</tracking>
Note the child elements in <states> node, there are the statuses that I wish to track. And, I name my Tracking Profile as "TrackEverything". For any other status which you wish to track, you can refer to here: http://msdn.microsoft.com/en-us/library/ee818716.aspx
Configure the Tracking Participant
Create a new service behavior or use back your existing service behavior for workflow service host. Add the ETW (Event Tracking for Windows) tracking participant to it and then set the above tracking profile work with it.
<behavior name="WorkflowServiceBehavior">
<serviceMetadata httpGetEnabled="true"/>
<serviceDebug includeExceptionDetailInFaults="true"/>
<sqlWorkflowInstanceStore connectionStringName="WorkflowInstanceStore"
hostLockRenewalPeriod="00:00:30"
runnableInstancesDetectionPeriod="00:00:05"
instanceCompletionAction="DeleteAll"
instanceLockedExceptionAction="AggressiveRetry"
instanceEncodingOption="GZip"
/>
<dataContractSerializer maxItemsInObjectGraph="2147483647"/>
<etwTracking profileName="TrackEverything"/>
</behavior>
Which Log to Monitor in Event Viewer?
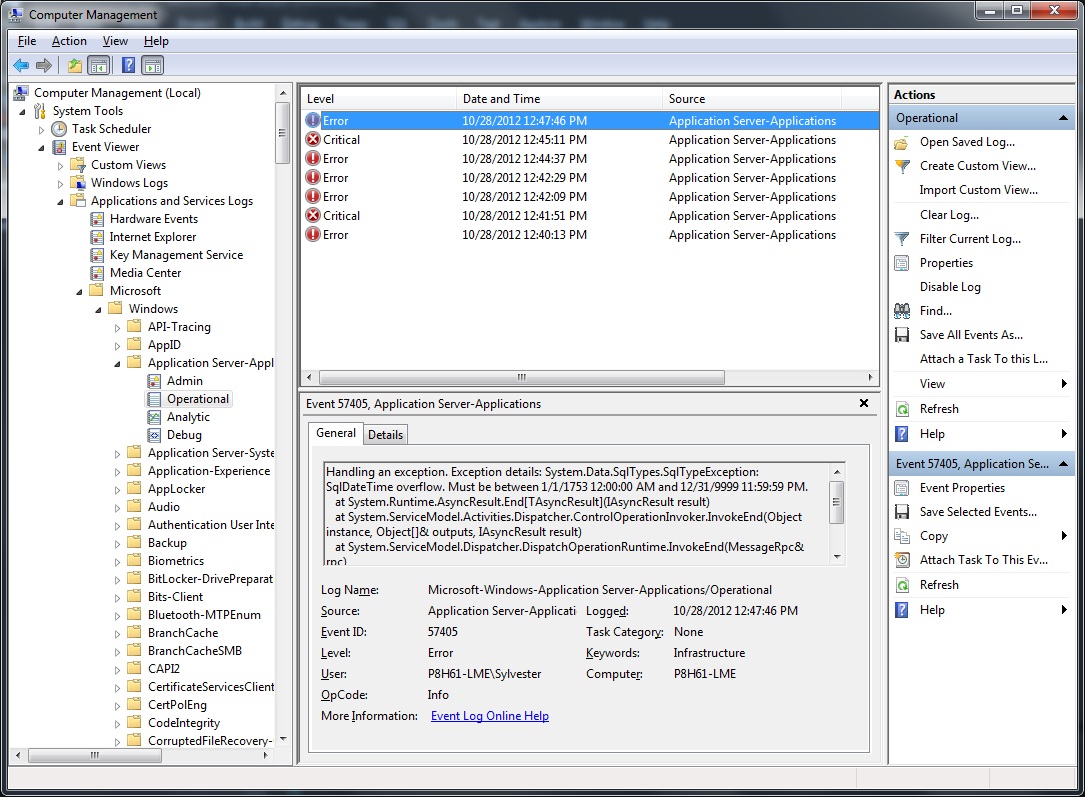
Open up the event viewer. Go to Applications and Services Logs \ Microsoft \ Application Server-Applications. You need to show Analytic and Debug logs. Here is where the ETW put the tracking record.

Now, let's purposely make a fail call to the workflow service. And, here is how the log look like.

If you do not like to have the log put into this default location, there is a way to configure ETW to put all the logs to a specific folder, please refer to MSDN.
If you do not like to read those default logs because they are too messy and the provided information is useless to you, we can actually perform a similar but custom tracking, which mean, we can perform another layer of filtering from the subscribed tracking record. I will share the detail in the next post.
In the workflow tracking and tracing, we need to know 3 things:
1. Tracking Record - the tracking info emitted from workflow runtime
2. Tracking Participant - the subscription of the tracking record
3. Tracking Profile - the filter of the subscription
I will skip all the theory and concept detail, feel free to read them from MSDN.
I will share the detail of how to configure it only in this topic.
In a normal event, we would want to track the unusual incident in workflow only. So, I want to track the workflow instance if it is faulted, suspended, terminated or unhandled exception had occurred only. How?
Configure the Tracking Profile
Open up the config file. Insert the following XML node into the <system.serviceModel> node.
<tracking>
<profiles>
<trackingProfile name="TrackEverything" implementationVisibility="All">
<workflow activityDefinitionId="*">
<workflowInstanceQueries>
<workflowInstanceQuery>
<states>
<state name="Faulted"/>
<state name="Suspended"/>
<state name="Terminated"/>
<state name="UnhandledException"/>
</states>
</workflowInstanceQuery>
</workflowInstanceQueries>
</workflow>
</trackingProfile>
</profiles>
</tracking>
Note the child elements in <states> node, there are the statuses that I wish to track. And, I name my Tracking Profile as "TrackEverything". For any other status which you wish to track, you can refer to here: http://msdn.microsoft.com/en-us/library/ee818716.aspx
Configure the Tracking Participant
Create a new service behavior or use back your existing service behavior for workflow service host. Add the ETW (Event Tracking for Windows) tracking participant to it and then set the above tracking profile work with it.
<behavior name="WorkflowServiceBehavior">
<serviceMetadata httpGetEnabled="true"/>
<serviceDebug includeExceptionDetailInFaults="true"/>
<sqlWorkflowInstanceStore connectionStringName="WorkflowInstanceStore"
hostLockRenewalPeriod="00:00:30"
runnableInstancesDetectionPeriod="00:00:05"
instanceCompletionAction="DeleteAll"
instanceLockedExceptionAction="AggressiveRetry"
instanceEncodingOption="GZip"
/>
<dataContractSerializer maxItemsInObjectGraph="2147483647"/>
<etwTracking profileName="TrackEverything"/>
</behavior>
Which Log to Monitor in Event Viewer?
Open up the event viewer. Go to Applications and Services Logs \ Microsoft \ Application Server-Applications. You need to show Analytic and Debug logs. Here is where the ETW put the tracking record.

Now, let's purposely make a fail call to the workflow service. And, here is how the log look like.
If you do not like to have the log put into this default location, there is a way to configure ETW to put all the logs to a specific folder, please refer to MSDN.
If you do not like to read those default logs because they are too messy and the provided information is useless to you, we can actually perform a similar but custom tracking, which mean, we can perform another layer of filtering from the subscribed tracking record. I will share the detail in the next post.
































